Announcing Twirl’s dbt Core Integration
At Twirl, we’re building an orchestrator that does all the hard bits of orchestration for you - whether you’re running Python or SQL, ingestion or transformations, ML or analytics, on structured or unstructured data. We believe you should always be able to use the right tool for the job, and combine them when needed, without sacrificing the developer experience.
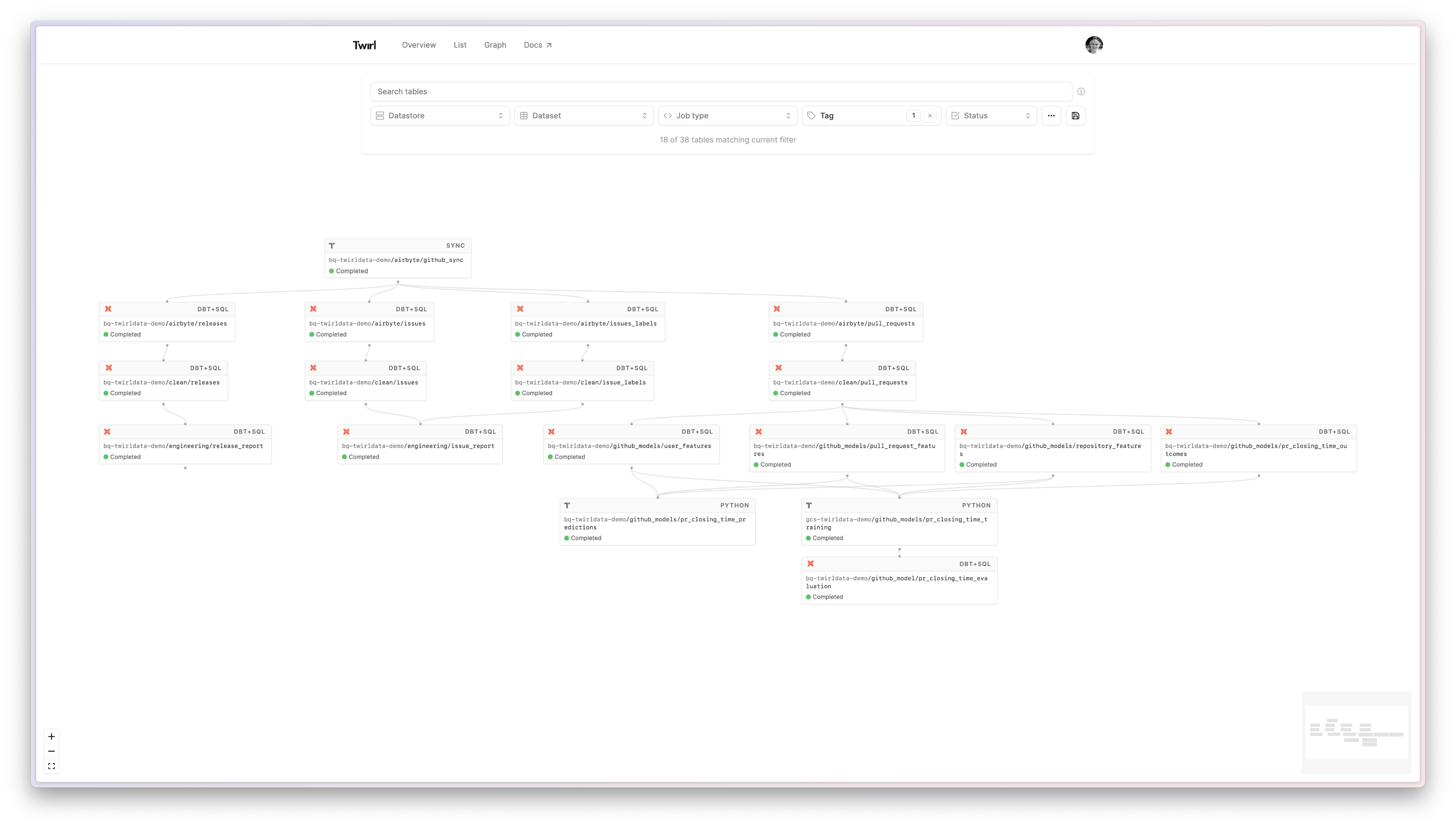
Towards that end, we are excited to announce that Twirl now integrates natively with dbt Core! This new feature allows you to seamlessly extend your Twirl project to include dbt models. It also means that your dbt models will benefit from everything that Twirl jobs get natively: a local development mode that works seamlessly across languages and databases, flexible and reactive scheduling, end-to-end lineage and monitoring.
Going beyond analytics transformations with Twirl + dbt
Until recently, most SQL transformations were written in custom frameworks or directly from an orchestrator. But in only a few years, dbt has emerged as the de facto standard for doing analytics transformations within the data warehouse.
However, lots of data work does not fit inside the analytics box: any kind of data ingestion job, training of a machine learning model or pushing data to a third-party service, requires execution outside of the data warehouse, and writing code outside of dbt. Most of this work is done in Python jobs that get triggered by an orchestrator and executed in containers.
That leaves analytics in a separate and isolated world. A common way to bridge the gap is to have your orchestrator trigger dbt. But that usually means having all the dbt jobs triggered together as one big blob in the middle of the DAG. You end up with no end-to-end lineage, and your code and logs spread out across multiple places. It becomes hard or impossible to develop pipelines that include both dbt models and other kinds of data processing, which discourages the reuse of existing pipelines and transformations.
Twirl’s native dbt integration solves these problems by allowing you to seamlessly embed your dbt models within Twirl. You get to keep your dbt project exactly as it is and can simply add Python or container jobs alongside it. Twirl will automatically understand the dependencies between your dbt models and Twirl jobs, giving you full end-to-end lineage in one place. You also get access to Twirl’s built-in dev mode, which works across dbt and Twirl jobs, meaning you can test mixed pipelines in a safe development environment before deploying them.
Mix and match Twirl tables and dbt models
One of the key benefits of Twirl’s dbt integration is the ability to seamlessly reference dbt models from Twirl jobs, and vice versa.
Referencing dbt Models from Twirl Python Jobs
To reference a dbt model from a Twirl Python job, you simply need to declare it as an input in your job’s manifest file using the twirl.Input function. For example:
# manifest.py
import twirl
twirl.manifest(
twirl.Table(
inputs=[
twirl.Input("daily_transactions"),
# Depends on the dbt model "daily_transactions"
],
...
)
)Here, the Twirl Python job is declaring a dependency on the daily_transactions dbt model. Twirl will ensure that the daily_transactions model is run before the Python job, and will make the model’s data available to the job at runtime.
Referencing Twirl Tables from dbt Models
Similarly, you can reference Twirl tables (i.e., tables created by Twirl’s Python, SQL or container jobs) from your dbt models using the twirl_ref macro. To use the twirl_ref macro, simply call it with the database name, schema name, and table name of the Twirl table you want to reference. For example:
--dbt_model.sql
SELECT
user_id,
status
FROM {{ twirl_ref('my_database', 'my_schema', 'users') }}Here, the dbt model references the users table created by a Twirl Python job. The twirl_ref macro resolves the correct table name based on your Twirl configuration and the current environment (dev vs. prod).
Development Mode
Out of the box, Twirl provides a safe development environment for running pipelines locally on real production data. Invoking twirl run updates the selected tables in dev mode, meaning inputs are read from production tables but outputs are written to a separate, personal dev dataset instead. This provides a safe development environment where you can test your changes with real data without the risk of impacting production.
With the new dbt integration, dev mode now works seamlessly across both Twirl jobs and dbt models. This means users can thoroughly test and debug their entire pipelines in a consistent way before deployment, which helps avoid the costly and time-consuming process of troubleshooting issues after something has already been pushed to production.
Advanced Scheduling for dbt Models
Twirl’s integration also brings advanced scheduling capabilities to your dbt models. You can now set up separate schedules for each model, without breaking into multiple sub-DAGs, for example:
- Run models continuously, appending new data in micro-batches
- Run only when any upstream dependency has new data
- Run some models hourly and others daily or weekly
- Run on a custom cron schedule
Here’s an example of setting an hourly schedule for a dbt model, just by adding the following lines to your dbt .yaml file:
models:
- name: users
config:
meta:
twirl:
trigger_condition:
type: at
cron_string: '0 * * * *'
cron_tz: 'Europe/Stockholm'Conclusion
At Twirl, we’re building an orchestration platform that empowers data teams to mix and match tools: the Twirl + dbt integration is a step in that direction, allowing data teams to build complex, multi-language data pipelines without having to worry about data movement and dependency management.
Whether you are an existing Twirl user who would like to bring in your dbt project, or an existing dbt user who has been looking for a way to run Python and dbt on a single platform, you can try us out at twirldata.com.
Have questions on Twirl + dbt? Please reach out at hello@twirldata.com!